
Modelamiento¶
Esta clase es el puntapié inicial para todo lo que nos estuvimos preparando durante el semestre, utilizar modelos matemáticos en conjuntos de datos. Hoy en día se habla mucho de Machine Learning y otros conceptos fancy.
Introducción¶
Machine Learning¶
Machine learning algorithms can figure out how to perform important tasks by generalizing from examples. This is often feasible and cost-effective where manual programming is not. As more data becomes available, more ambitious problems can be tackled (Pedro Domingos: A Few Useful Things to Know about Machine Learning).
Estudia y construye sistemas que pueden aprender de los datos, más que seguir instrucciones explícitamente programadas.
Machine Learning es un conjunto de técnicas y modelos que permiten el modelamiento predictivo de datos, reunidas a partir de la intersección de elementos de probabilidad, estadística e inteligencia artificial.
Típicamente, alguien que trabaja en Machine Learning está en la Academia y busca realizar investigación y publicar artículos.
Pregunta fundamental: ¿Qué conocimiento emerge a partir de los datos? ¿Qué modelo/técnica otorga la mejor predicción para estos datos?
Data Science¶
Se preocupa de la practicidad de resolver problemas complejos utilizando datos.
Data Science es la aplicación de diversas técnicas de modelamiento con un fin específico. También se conoce como eScience.
La base de datos a utilizar no ha sido necesariamente creada.
Típicamente, un data scientist se encuentra en la industria, buscando automatizar un análisis complejo para un cliente (interno o externo).
Pregunta fundamental: ¿Qué puedo decir de X a partir de los datos?
Inteligencia Artificial¶
Tiene por objetivo hacer que el computador ejecute tareas para las cuales el hombre, en un contexto dado, es actualmente mejor que la máquina.
Es un concepto más amplio que Machine Learning, en el sentido de definir el concepto de inteligencia.
Algunos enfoques de inteligencia considerean que tiene que ver principalmente con acciones racionales. Que un agente inteligente es capaz de percibir y actuar, realizando la mejor acción posible en una situación dada.
Pregunta fundamental: ¿Puedo modelar el problema pero que su resolución no es razonablemente factible por algoritmos existentes?
Big Data¶
Caracterizado por 4 V:
Volumen: ¿Cuántos datos se requiere procesar? ¿Terabytes, Exabytes, Zettabytes?
Variedad: ¿Qué patrón siguen los datos? ¿SQL o noSQL?
Velocidad: ¿Con que velocidad podemos procesar los datos? ¿A qué velocidad se generan?
Veracidad: ¿Qué tan confiables son los datos?
Pregunta fundamental: ¿Cómo proceso esta monstruosidad de datos?
También es usual ver en LinkedIn, foros y/o blogs una serie de infografías tratando de definir o separar conceptos. Al no existir límites fijos, estas infografías suelen variar entre autores. No creas todo lo que ves.
Opinión personal: No todo lo que brilla es oro. No soy fan de estas infografías o diagramas.
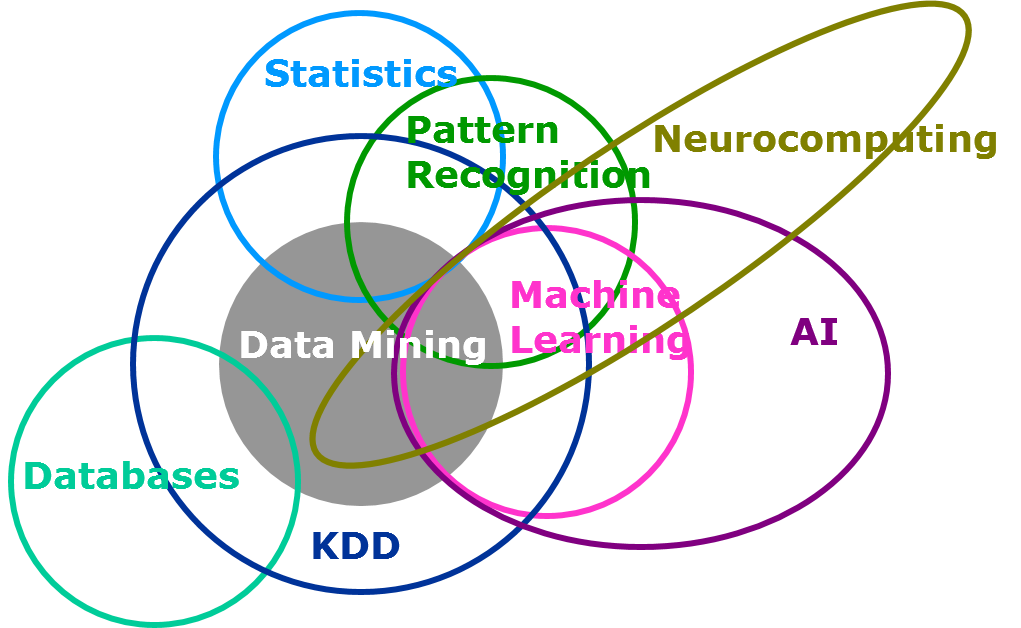
¿Estadística separada de Machine Learning? No lo creo.
Aunque hay algunos diagramas más conservadores y no tan estrafalarios.
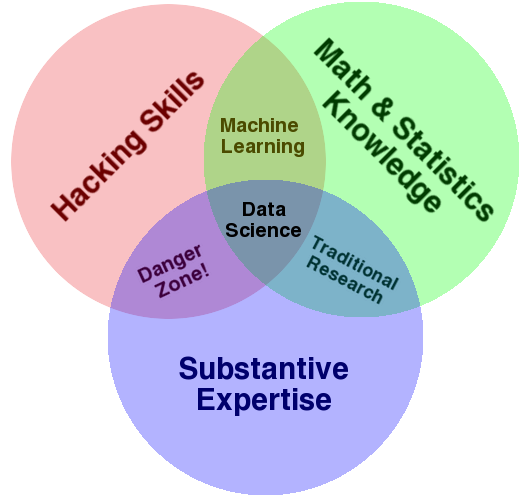
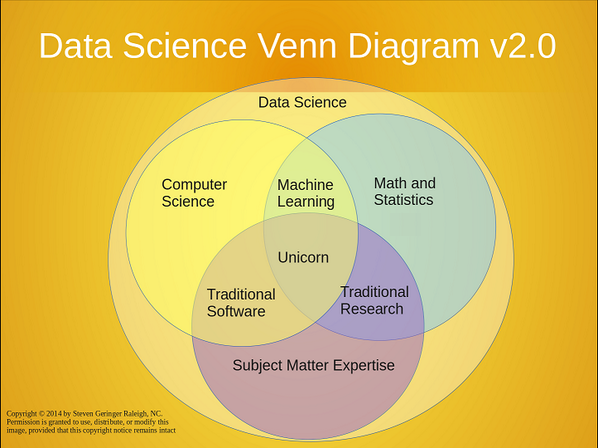
Aplicaciones¶
Detección de Spam¶
A partir de correos previamente clasificados como spam y no-spam, identificar futuros correos en spam de aquellos que no son spam.

Detección de Fraude con Tarjeta de crédito¶
Dado el historial de transacciones de un cliente en un mes, identificar transacciones que realizadas por el cliente y transacciones fraudulentas realizadas por terceros.

Reconocimiento de dígitos¶
Dado un código zip escrito en un sobre, identificar cada dígito manuscrito para automatizar la clasificación y despacho de correo.

Reconocimiento de Voz¶
Dada una orden vocal de un usuario, idenficar el requerimiento específico realizado.
Detección facial¶
Dada una colección de fotos digitales, identificar en cuáles fotos y en qué sectores aparece una persona. Más difícil, dada una colección de fotos etiquetadas para una cierta persona, identificar en cuales fotos aparece esa persona.
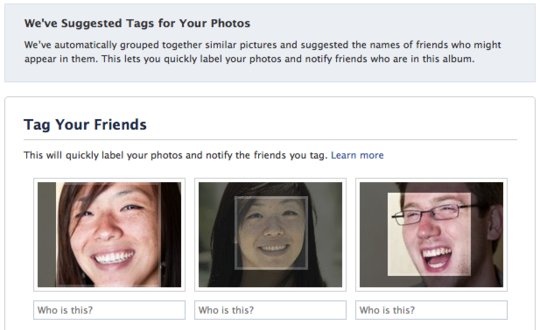
Recomendación de Productos¶
Dado un historial de compra para un cliente y un largo inventario de productos, identificar cuáles productos pueden interesarle al cliente en su próxima compra.
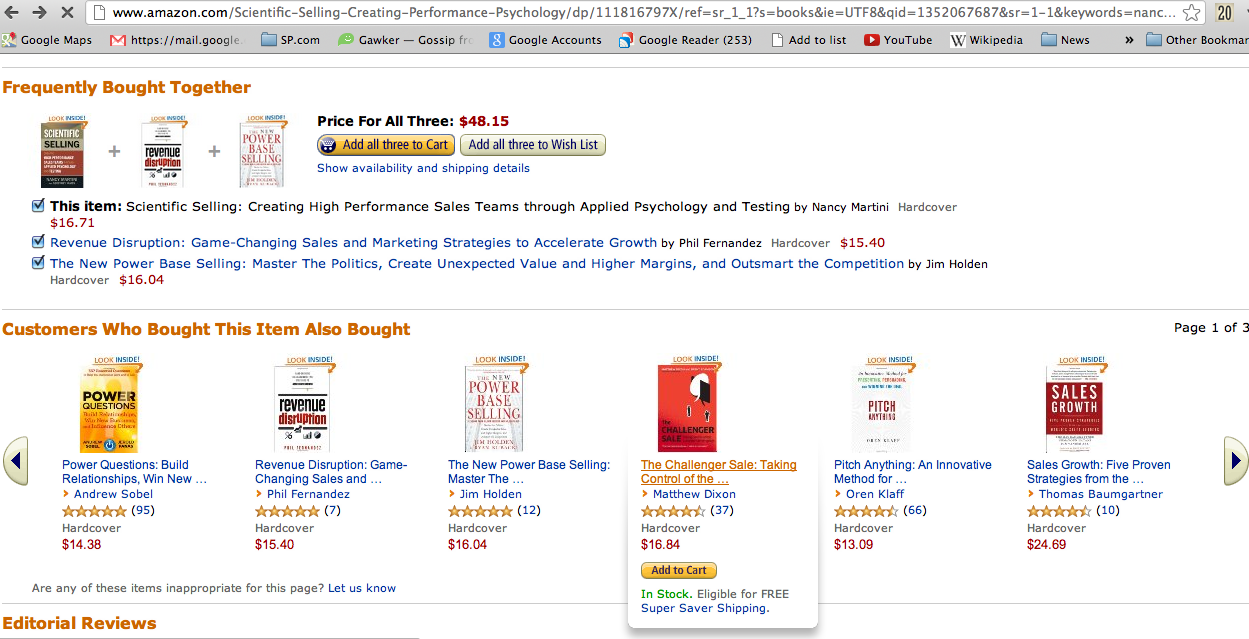
Diagnóstico médico¶
Dado un conjunto de síntomas exhibidos por un paciente y una base de casos anónima, predecir si el paciente tiene una enfermedad (y cuál).
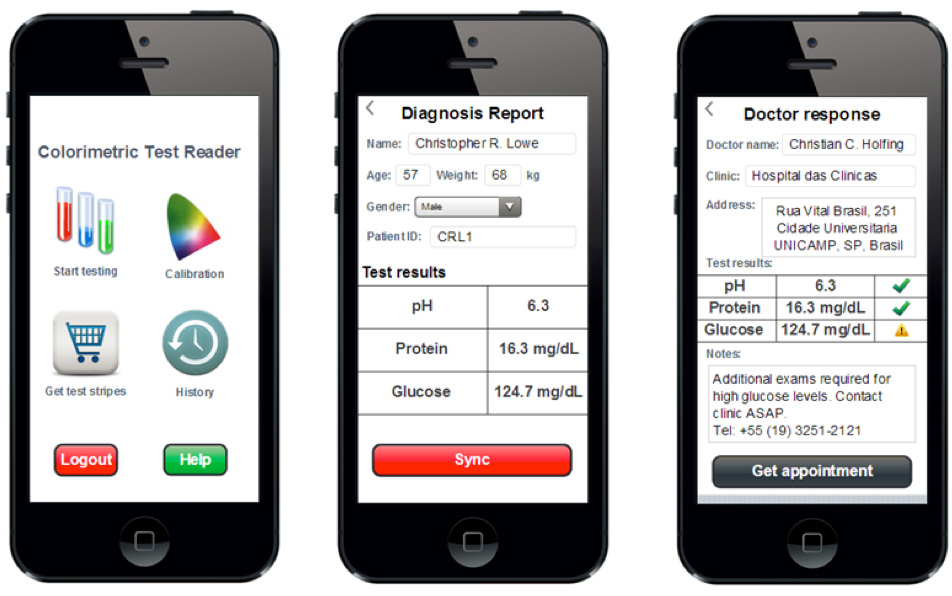
Mercado de Acciones¶
Dadas las fluctuaciones pasadas y presentes de una cierta acción, predecir si la acción debe comprarse, mantenerse o venderse.
Segmentación de Mercado¶
Dado un historial de comportamientos pasados de clientes, identificar cuáles clientes exhibirán un cierto comportamiento (de compra) en el futuro.

Modelamiento¶
¿Qué es un modelo?¶
Un modelo es
Una representación abstracta y conveniente de un sistema.
Una simplificación del mundo real.
Un medio de exploración y de explicación para nuestro entendimiento de la realidad.
Un modelo NO es
Igual al mundo real.
Un sustituto para mediciones o experimentos.
¿Por qué utilizar módelos?¶
Permiten reproducir escalas temporales o espaciales donde las mediciones o los experimentos son costosos, difíciles o imposibles.
Ejemplo: deriva continental, impacto de asteroides, evolución de enfermedades, etc.
Es mejor que no hacer nada o confiar en juicios dudosos de terceros.
Ejemplo: Predicción meteorológica versus danza de la lluvia.
Objetivos del modelamiento¶
Ayudar al diseño de experimentos y mediciones.
Condensar entendimiento al forzar la abstracción, integración y formalización de ideas científicas.
Permitir la realización de experimentos virtuales.
Divulgar conocimiento científico a no-expertos.
Realizar predicciones.
El modelamiento nunca es un objetivo en sí mismo.
Algunos principios básicos¶
Un mismo fenómeno físico puede tener distintos modelos, cada uno apropiado para el estudio de un cierto aspecto del fenómeno.
Modelamiento require tiempo: es necesario determinar el nivel de complejidad en función los resultados deseados y del tiempo disponible.
GIGO: Garbage In = Garbage Out: Un buen modelo no compensa malos datos de entrada.
El mundo es demasiado complejo para poder modelarlo perfectamente.
Todo modelo es una simplificación de la realidad.
Modelos complementan otras formas de conocimiento (experimentos, mediciones)
Que algo se pueda simular, no significa que se corresponda con la realidad.
Validación completa del un modelo es imposible, al igual que cualquier teoría.
"All models are wrong,
some are useful" - George Box"
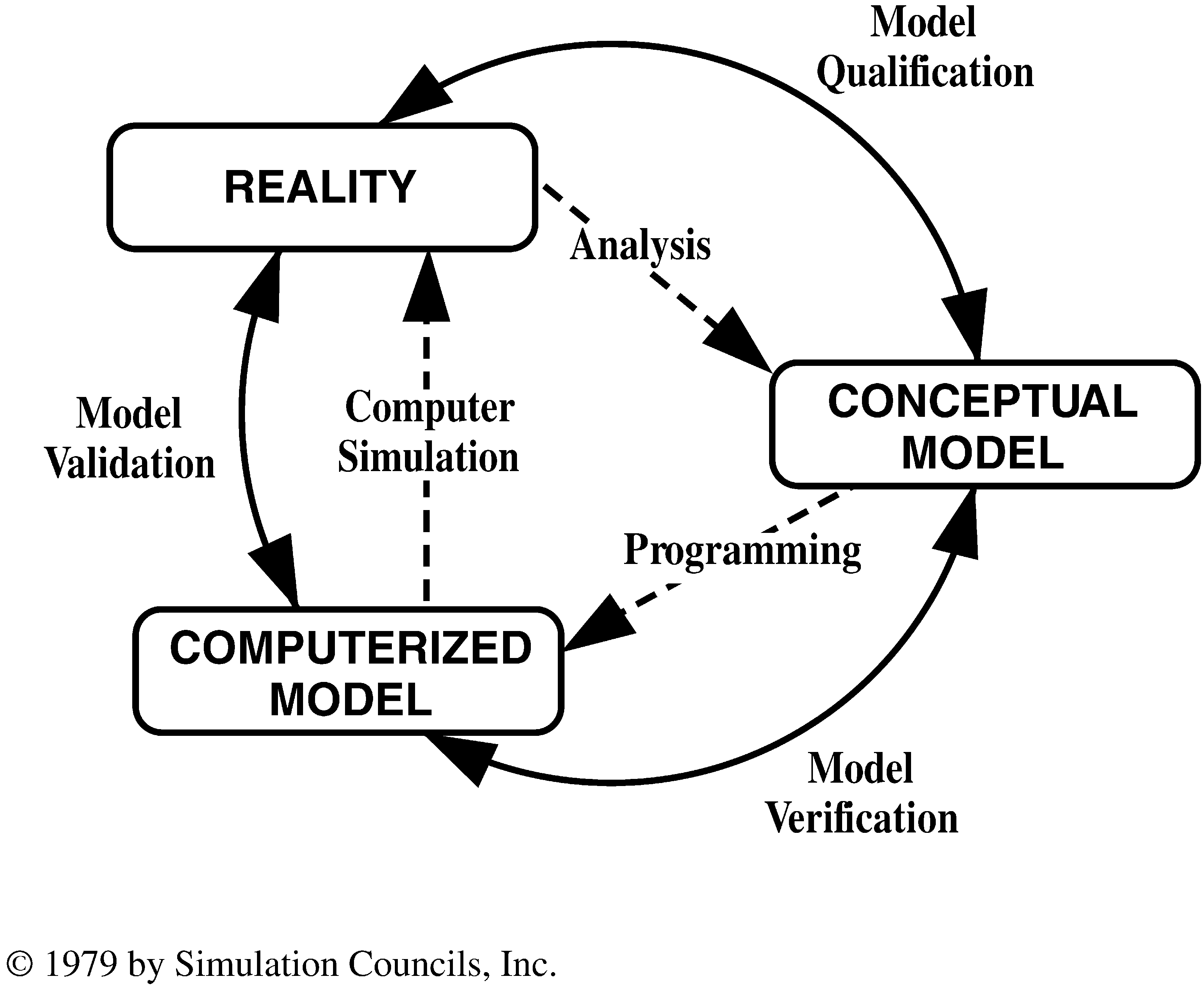
Etapas del Modelamiento¶
Meta: Definir el propósito del modelo.
Modelar: Desarrollar el modelo conceptual.
Afinar: Seleccionar el tipo de modelo y la escala.
Implementar: Realizar la implementación numérica del modelo conceptual.
Calibrar: Estimar los parámetros requeridos por el modelo.
Analizar: Evaluar el modelo con análisis de sensitividad e incertidumbre.
Validar: Comparar las predicciones del modelo con mediciones reales. Requiere parámetros y mediciones reales.
Utilizar: Aplicar el modelo al propósito. Requiere parámetros reales.
"Everyone believes the recorded data,
except the scientist that record it.
No one believes the model,
except for the scientist that created it."
- Unknown
"If you're doing an experiment,
you should report everything
that you think might make it invalid —
not only what you think is right about it;
other causes that could possibly explain
your results; and things you thought
of that you've eliminated by some
other experiment, and how they worked —
to make sure the other fellow
can tell they have been eliminated."
- Richard Feynman.
Debriefing¶
El Debriefing es un proceso semi-estructurado, que permite analizar una cierta actividad que ha sido llevada a cabo. Se realiza una serie de preguntas que permite que los participantes refleccionen en lo ocurrido, los resultados y metas, para mejorar el desempeño futuro.
Durante la vida universitaria se puede utilizar en situaciones coloquiales.
Certámenes y Tareas:
¿Cuál era la solución correcta?
¿Porqué no llegué a la solución?
¿Cómo debería haber estudiado para optimizar mi nota?
Proyectos en grupo:
¿Existieron problemas en el grupo?
¿Qué podría haberse hecho de mejor forma?
¿Cómo fue la interacción entre los integrantes?
¿Estamos conformes con el resultado dado el tiempo invertido?
Debriefing no altera resultados pasados, pero permite mejorar incrementalmente y detectar errores metodológicos.
Fuentes de Error¶
Existen múltiples fuentes de error:
Humana
Instrumental
Algo importante a considerar es que toda medición es siempre indirecta. Lo que se mide no es necesariamente lo que se necesita. Por ejemplo:
Longitud: comparación directa (regla), comparación indirecta (sensor laser).
Temperatura: mediante dilatación (termómetro tradicional), cambio de densidad (termómetro de Galileo), o cambio de resistencia eléctrica (termómetro digital).
Fuente de Error Humana¶
La definición del problema a resolver está dado por el cliente, y la respuesta contiene:
Deformación profesional.
Expectativas a priori.
Confianza infinita (o nula) en los métodos numéricos.
Pueden ser del tipo:
Medición: Falta de apego a protocolos e imprecisión.
Modelamiento Matemático: Errores conceptuales, de unidades, de condiciones de frontera o características de la problemática. Para quien tiene un martillo, todo parece un clavo.
Modelamiento Numérico: La discretización de un sistema de ecuaciones introduce un error que suele olvidarse.
Implementación Numérica: Testeo deficiente permite que bugs permanezcan ocultos en la implementación.
Interpretación: Confianza ciega en la caja negra.
Fuente de Error debido a la Incerteza en Parámetros¶
Los parámetros rara vez se conocen con buena precisión, incluso cuando el modelo físico-matemático ha sido bien definido. Por ello, siempre es necesario tomar un enfoque conservador en la incerteza de los parámetros involucrados dependiendo de la aplicación del modelo.
Por ejemplo, en el caso de minería subterránea:
Si el problema involucra seguridad en los túneles mineros, se utiliza un modelo conservador que subestima los parámetros físicos de la roca: : la roca del modelo es menos resistente que en la realidad. Si el modelo indica que el túnel es resistente, tenemos confianza que en la realidad el tunel es seguro.
Si el problema involucra factibilidad de la técnica extractiva, se utiliza un modelo que sobreestima los parámetros físicos de la roca: la roca del modelo es más resistente que en la realidad. Si el modelo indica que la roca se quiebra adecuadamente durante el caving, tenemos confianza que la roca se quiebra durante el caving.
Otro tema a considerar es que los modelos nunca tienen precisión infinita. Por ejemplo, en minería:
Si consideramos que los parámetros físicos de la roca son constantes en todo el dominio en análisis, no se considera las variaciones que existen naturalmente.
Si consideramos que los parámetros físicos de la roca varían punto a punto en todo el dominio de análisis, es necesario conocer dicho valor, lo cual resulta imposible de mapear tridimensionalmente.
Algoritmos ML¶
Hay 4 grandes familias de problemas en Machine Learning:
Clasificación
Regresión
Clustering
Extracción de Reglas
Regresión¶
Similar a clustering, pero donde los datos están etiquetados con un valor real. El desafío es asignar la etiqueta correcta a datos sin etiquetar.
Ejemplos:
Predicción de precio en mercado de acciones.
Predicción de precio de casa/departamento basado en características.
Clasificación¶
Se conocen como están etiquetados (asignados a una clase) algunos de los elementos. El desafío es asignar la etiqueta correcta a datos sin etiquetar.
Ejemplos:
Clasificación de Spam.
Clasificación de Fraudes.
Reconocimiento de Dígitos
Diágnostico Médico.
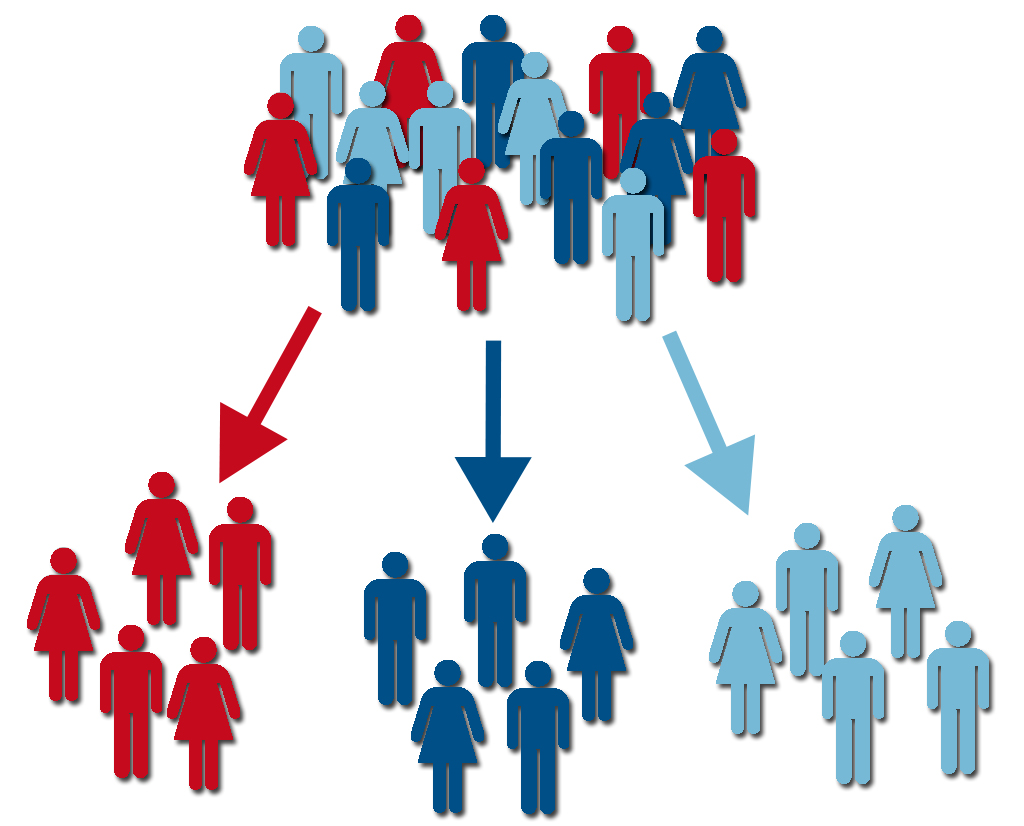
Clustering¶
Los datos no se encuentran etiquetados (no existe un valor \(y\) para predecir), pero se busca dividir el conjunto de datos basados en alguna medida de similaridad o estructura de los datos. El desafío es encontrar cómo se podrían separar los datos a partir de sus datos sin saber cómo ni porqué se podrían separar.
Ejemplos:
Ordenar fotos según persona que aparece en rostros.
Segmentación de mercados.
Compresión de información.
Extracción de Reglas¶
Los datos se usan para la extracción de reglas o relaciones previamente desconocidas entre los datos. A menudo no existe una relación predictiva entre los datos, sino que simplemente existe una relación no causal entre los atributos de los datos. El desafío es encontrar las relaciones no predictivas entre los datos, sin conocerlas a priori.
Ejemplos:
Reconocimiento de Voz.
Recomendación de Productos.
¡Existe un sitio con una animación increíble!: http://www.r2d3.us/
Consejos¶
Excelente artículo de Pedro Domingos: A Few Useful Things to Know about Machine Learning.
Learning = Representation + Evaluation + Optimization
La meta fundamental es generalizar a partir de los ejemplos.
Sólo tener datos no es suficiente.
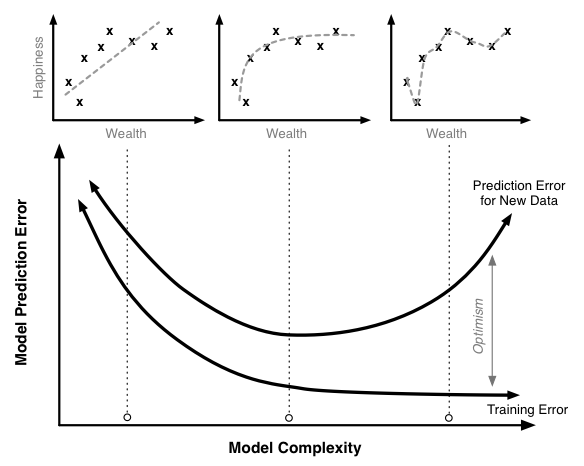
Cuidado con overfitting en el modelo.
La intuición es difícil en grandes dimensiones.