
Combinando Datos¶
¿Te imaginas como las grandes compañías o gobiernos almacenan sus datos?
No, no es en un excel gigante en un pendrive.
Es importante saber como modificar o crear valor a través de distintas tablas de datos, por lo que esta clase se centrará en hacer esto, motivando a partir del uso de bases de datos relacionales.
Base de Datos¶
Una Base de Datos es un conjunto de datos almacenados en una computadora (generalmente un servidor, máquina virtual, etc.) y que poseen una estructura tal que sean de fácil acceso.
Base de Datos Relacional¶
Es el tipo de base de datos más ampliamente utilizado, aunque existen otros tipos de bases de datos para fines específicos. Utiliza una estructura tal que es posible identificar y acceder a datos relacionados entre si. Generalmente una base de datos relacional está organizada en tablas.
Las tablas están conformadas de filas y columnas. Cada columna posee un nombre y tiene un tipo de dato específico, mientras que las filas son registros almacenados.
Por ejemplo, la siguiente tabla tiene tres columnas y cuatro registros. En particular, la columna age tiene tipo INTEGER y las otras dos tipo STRING.

¿Este formato de datos te parece familar?
¿Qué es SQL?¶
Sus siglas significan Structured Query Language (Lenguaje de Consulta Estructurada) es un lenguaje de programación utilizado para comunicarse con datos almacenados en un Sistema de Gestión de Bases de Datos Relacionales (Relational Database Management System o RDBMS). Posee una sintaxis muy similar al idioma inglés, con lo cual se hace relativamente fácil de escribir, leer e interpretar.
Hay distintos RDBMS entre los cuales la sintaxis de SQL difiere ligeramente. Los más populares son:
SQLite
MySQL / MariaDB
PostgreSQL
Oracle DB
SQL Server
En una empresa de tecnología hay cargos especialmente destinados a todo lo que tenga que ver con bases de datos, por ejemplo: creación, mantención, actualización, obtención de datos, transformación, seguridad y un largo etc.
Los matemáticos en la industria suelen tener cargos como Data Scientist, Data Analyst, Data Statistician, Data X (reemplace X con algo fancy tal de formar un cargo que quede bien en Linkedin), en donde lo importante es otorgar valor a estos datos. Por ende, lo mínimo que deben satisfacer es:
Entendimiento casi total del modelo de datos (tablas, relaciones, tipos, etc.)
Seleccionar datos a medida (queries).
Modelo de datos¶
Es la forma en que se organizan los datos. En las bases de datos incluso es posible conocer las relaciones entre tablas. A menudo se presentan gráficamente como en la imagen de abajo (esta será la base de datos que utilizaremos en los ejericios del día de
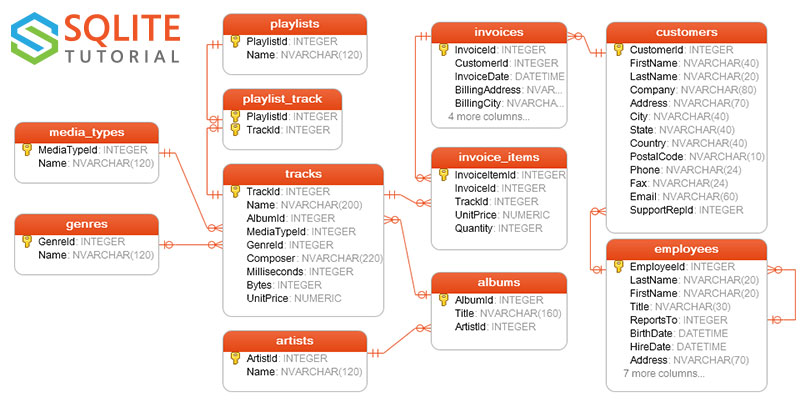
Esta base de datos se conoce con el nombre de chinook database. La descripción y las imágenes se pueden encontrar aquí.
En la figura anterior, existen algunas columnas especiales con una llave al lado de su nombre. ¿Qué crees que significan?
Las 11 tablas se definen de la siguiente forma (en inglés):
employeestable stores employees data such as employee id, last name, first name, etc. It also has a field named ReportsTo to specify who reports to whom.customerstable stores customers data.invoices&invoice_itemstables: these two tables store invoice data. Theinvoicestable stores invoice header data and theinvoice_itemstable stores the invoice line items data.artiststable stores artists data. It is a simple table that contains only artist id and name.albumstable stores data about a list of tracks. Each album belongs to one artist. However, one artist may have multiple albums.media_typestable stores media types such as MPEG audio file, ACC audio file, etc.genrestable stores music types such as rock, jazz, metal, etc.trackstable store the data of songs. Each track belongs to one album.playlists&playlist_track tables:playliststable store data about playlists. Each playlist contains a list of tracks. Each track may belong to multiple playlists. The relationship between theplayliststable andtrackstable is many-to-many. Theplaylist_tracktable is used to reflect this relationship.
SQL - pandas¶
import os # Funcionalidades con sistemas operativos
import sqlite3 # Solo auxiliar para motivar la clase
import pandas as pd
En la carpeta data se encuentra el archivo chinook.db, que es básicamente una base de datos sql. Definiremos una simple función con tal de recibir una query en formato str de python y retorne el resultado de la query en un dataframe de pandas.
def chinook_query(query):
# Crear un conector
conn = sqlite3.connect(os.path.join('..', 'data', 'chinook.db'))
# Retorna un dataframe
return pd.read_sql_query(query, con=conn)
# Ver todas las tablas de la base de datos
chinook_query(
"""
SELECT name
FROM sqlite_master
WHERE type='table'
"""
)
| name | |
|---|---|
| 0 | albums |
| 1 | sqlite_sequence |
| 2 | artists |
| 3 | customers |
| 4 | employees |
| 5 | genres |
| 6 | invoices |
| 7 | invoice_items |
| 8 | media_types |
| 9 | playlists |
| 10 | playlist_track |
| 11 | tracks |
| 12 | sqlite_stat1 |
En el ejemplo anterior resulta muy importante no mezclar tipos de comillas distintos. Si se define un string comenzando y terminando con " todas las comillas a usar en el interior deben de ser ', o viceversa.
Agregar nuevas Columnas¶
Es usual que desde una misma tabla/dataframe se desee agregar columnas. Veamos la tabla de empleados para motivar algunos ejemplos.
employees = chinook_query("select * from employees")
employees.head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | Canada | T5K 2N1 | +1 (780) 428-9482 | +1 (780) 428-3457 | andrew@chinookcorp.com |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | Canada | T2P 2T3 | +1 (403) 262-3443 | +1 (403) 262-3322 | nancy@chinookcorp.com |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com |
| 3 | 4 | Park | Margaret | Sales Support Agent | 2.0 | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com |
| 4 | 5 | Johnson | Steve | Sales Support Agent | 2.0 | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com |
Ejemplo: Crear una nueva columna que sea Title - FirstName Lastname.
En el caso de un solo empleado la tarea es sencilla:
title, fname, lname = employees.loc[0, ["Title", "FirstName", "LastName"]].values
print(f"{title} - {fname} {lname}")
General Manager - Andrew Adams
Primera idea: Iterar por cada fila.
pandas permite iterar por filas utilizando el método iterrows, el cual disponibiliza el index y la fila como una pd.Series en cada iteración.
for idx, row in employees.iterrows():
print(f"type(idx): {type(idx)}")
print(f"type(row): {type(row)}\n")
print(f"idx: {idx}\n")
print(f"row:\n\n{row}")
break
type(idx): <class 'int'>
type(row): <class 'pandas.core.series.Series'>
idx: 0
row:
EmployeeId 1
LastName Adams
FirstName Andrew
Title General Manager
ReportsTo NaN
BirthDate 1962-02-18 00:00:00
HireDate 2002-08-14 00:00:00
Address 11120 Jasper Ave NW
City Edmonton
State AB
Country Canada
PostalCode T5K 2N1
Phone +1 (780) 428-9482
Fax +1 (780) 428-3457
Email andrew@chinookcorp.com
Name: 0, dtype: object
# Copia del dataframe original
employees_copy1 = employees.copy()
for idx, row in employees_copy1.iterrows():
full_name = f"{row['Title']} - {row['FirstName']} {row['LastName']}"
employees_copy1.loc[idx, "full_name"] = full_name # Asignar valores con loc
employees_copy1.head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | full_name | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | Canada | T5K 2N1 | +1 (780) 428-9482 | +1 (780) 428-3457 | andrew@chinookcorp.com | General Manager - Andrew Adams |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | Canada | T2P 2T3 | +1 (403) 262-3443 | +1 (403) 262-3322 | nancy@chinookcorp.com | Sales Manager - Nancy Edwards |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com | Sales Support Agent - Jane Peacock |
| 3 | 4 | Park | Margaret | Sales Support Agent | 2.0 | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com | Sales Support Agent - Margaret Park |
| 4 | 5 | Johnson | Steve | Sales Support Agent | 2.0 | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com | Sales Support Agent - Steve Johnson |
Idea 2: Uilizar apply
employees_copy2 = employees.copy()
employees_copy2.apply(lambda row: f"{row['Title']} - {row['FirstName']} {row['LastName']}", axis=1) # Retorna una serie
0 General Manager - Andrew Adams
1 Sales Manager - Nancy Edwards
2 Sales Support Agent - Jane Peacock
3 Sales Support Agent - Margaret Park
4 Sales Support Agent - Steve Johnson
5 IT Manager - Michael Mitchell
6 IT Staff - Robert King
7 IT Staff - Laura Callahan
dtype: object
Para asignarlo basta con:
employees_copy2["FullName"] = employees.apply(lambda row: f"{row['Title']} - {row['FirstName']} {row['LastName']}", axis=1)
employees_copy2.head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | FullName | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | Canada | T5K 2N1 | +1 (780) 428-9482 | +1 (780) 428-3457 | andrew@chinookcorp.com | General Manager - Andrew Adams |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | Canada | T2P 2T3 | +1 (403) 262-3443 | +1 (403) 262-3322 | nancy@chinookcorp.com | Sales Manager - Nancy Edwards |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com | Sales Support Agent - Jane Peacock |
| 3 | 4 | Park | Margaret | Sales Support Agent | 2.0 | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com | Sales Support Agent - Margaret Park |
| 4 | 5 | Johnson | Steve | Sales Support Agent | 2.0 | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com | Sales Support Agent - Steve Johnson |
Si estás en medio de una concatenación de métodos el método assign es genial. Al principio puede confundir pero básicamente asigna nuevas columnas sin necesidad del paso anterior.
employees.assign(
FullName=lambda x: x.apply(lambda row: f"{row['Title']} - {row['FirstName']} {row['LastName']}", axis=1)
).head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | FullName | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | Canada | T5K 2N1 | +1 (780) 428-9482 | +1 (780) 428-3457 | andrew@chinookcorp.com | General Manager - Andrew Adams |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | Canada | T2P 2T3 | +1 (403) 262-3443 | +1 (403) 262-3322 | nancy@chinookcorp.com | Sales Manager - Nancy Edwards |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com | Sales Support Agent - Jane Peacock |
| 3 | 4 | Park | Margaret | Sales Support Agent | 2.0 | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com | Sales Support Agent - Margaret Park |
| 4 | 5 | Johnson | Steve | Sales Support Agent | 2.0 | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com | Sales Support Agent - Steve Johnson |
Ten en consideración que el método assign retorna una copia.
Idea 3: Operaciones entre series, y como los dataframes se componen de series todo es más fácil!
employees["Title"] + " - " + employees["FirstName"] + " " + employees["LastName"]
0 General Manager - Andrew Adams
1 Sales Manager - Nancy Edwards
2 Sales Support Agent - Jane Peacock
3 Sales Support Agent - Margaret Park
4 Sales Support Agent - Steve Johnson
5 IT Manager - Michael Mitchell
6 IT Staff - Robert King
7 IT Staff - Laura Callahan
dtype: object
employees_copy3 = employees.copy()
employees_copy3["FullName"] = employees_copy3["Title"] + " - " + employees_copy3["FirstName"] + " " + employees_copy3["LastName"]
employees_copy3.head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | FullName | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | Canada | T5K 2N1 | +1 (780) 428-9482 | +1 (780) 428-3457 | andrew@chinookcorp.com | General Manager - Andrew Adams |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | Canada | T2P 2T3 | +1 (403) 262-3443 | +1 (403) 262-3322 | nancy@chinookcorp.com | Sales Manager - Nancy Edwards |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com | Sales Support Agent - Jane Peacock |
| 3 | 4 | Park | Margaret | Sales Support Agent | 2.0 | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com | Sales Support Agent - Margaret Park |
| 4 | 5 | Johnson | Steve | Sales Support Agent | 2.0 | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com | Sales Support Agent - Steve Johnson |
Finalmente, comparemos estos métodos:
%%timeit
for idx, row in employees_copy1.iterrows():
full_name = f"{row['Title']} - {row['FirstName']} {row['LastName']}"
employees_copy1.loc[idx, "full_name"] = full_name
2.69 ms ± 8.17 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit
employees_copy2["FullName"] = employees_copy2.apply(lambda row: f"{row['Title']} - {row['FirstName']} {row['LastName']}", axis=1)
806 µs ± 1.69 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%%timeit
employees_copy2.assign(
FullName=lambda x: x["Title"] + " - " + x["FirstName"] + " " + x["LastName"]
)
757 µs ± 1.48 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%%timeit
employees_copy3["FullName"] = employees_copy3["Title"] + " - " + employees_copy3["FirstName"] + " " + employees_copy3["LastName"]
663 µs ± 9.64 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
¿Cambia la cosa o no? Sobretodo en el primer método, la iteración es considerablemente más lenta. La diferencia de tiempo con las otras metodologías es despreciable con este dataset, aunque la literatura considera que los métodos vectorizados (como el último) generalmente son mejores.
Concatenar¶
Imagina que tienes varias tablas con las mismas columnas y quieres unirlas en una grande. La función concat está diseñada para esta labor.
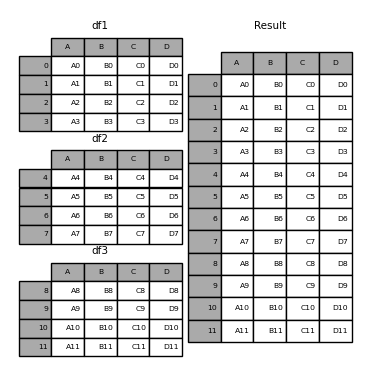
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
pd.concat([df1, df2, df3])
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 |
| 6 | A6 | B6 | C6 | D6 |
| 7 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
Un método similar es .append(), el cual concatena a lo largo del axis=0, es decir, a través de los índices.
df1.append([df2, df3])
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 |
| 6 | A6 | B6 | C6 | D6 |
| 7 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
Si los dataframes tienen distintas columnas no es impedimento para concatenarlas.

df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
pd.concat([df1, df4], axis=0, sort=False)
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN |
| 2 | A2 | B2 | C2 | D2 | NaN |
| 3 | A3 | B3 | C3 | D3 | NaN |
| 2 | NaN | B2 | NaN | D2 | F2 |
| 3 | NaN | B3 | NaN | D3 | F3 |
| 6 | NaN | B6 | NaN | D6 | F6 |
| 7 | NaN | B7 | NaN | D7 | F7 |
¿Quieres que se agreguen columnas dependiendo de los index que tienen cada dataframe?
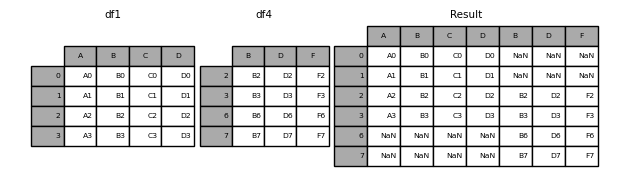
pd.concat([df1, df4], axis=1, sort=False)
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN | NaN | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
| 6 | NaN | NaN | NaN | NaN | B6 | D6 | F6 |
| 7 | NaN | NaN | NaN | NaN | B7 | D7 | F7 |
Unir¶
En pandas es posible unir dos tablas sin la necesidad de iterar fila por fila. La funcionalidad la entrega el método merge.
Ejemplo: En la base datos chinook existen las tablas albums y artists. ¿Cómo agregar el nombre del artista a la tabla de álbumes?
artists = chinook_query("select * from artists")
albums = chinook_query("select * from albums")
display(artists.head())
display(albums.head())
| ArtistId | Name | |
|---|---|---|
| 0 | 1 | AC/DC |
| 1 | 2 | Accept |
| 2 | 3 | Aerosmith |
| 3 | 4 | Alanis Morissette |
| 4 | 5 | Alice In Chains |
| AlbumId | Title | ArtistId | |
|---|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You | 1 |
| 1 | 2 | Balls to the Wall | 2 |
| 2 | 3 | Restless and Wild | 2 |
| 3 | 4 | Let There Be Rock | 1 |
| 4 | 5 | Big Ones | 3 |
Por el modelo de datos anterior sabemos que ambas tablas están relacionadas a través de la columna ArtistId. Iterando haríamos algo así:
albums_copy1 = albums.copy()
for idx, row in artists.iterrows():
artist_name = artists.loc[lambda x: x["ArtistId"] == row["ArtistId"], "Name"].iloc[0] # Acceder al string
albums_copy1.loc[idx, "ArtistName"] = artist_name
albums_copy1.head()
| AlbumId | Title | ArtistId | ArtistName | |
|---|---|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You | 1 | AC/DC |
| 1 | 2 | Balls to the Wall | 2 | Accept |
| 2 | 3 | Restless and Wild | 2 | Aerosmith |
| 3 | 4 | Let There Be Rock | 1 | Alanis Morissette |
| 4 | 5 | Big Ones | 3 | Alice In Chains |
Con el método merge todo es más sencillo.
albums.merge(artists, how="left", on="ArtistId").head()
| AlbumId | Title | ArtistId | Name | |
|---|---|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You | 1 | AC/DC |
| 1 | 2 | Balls to the Wall | 2 | Accept |
| 2 | 3 | Restless and Wild | 2 | Accept |
| 3 | 4 | Let There Be Rock | 1 | AC/DC |
| 4 | 5 | Big Ones | 3 | Aerosmith |
Comparemos los tiempos de ejecución.
%%timeit
for idx, row in artists.iterrows():
artist_name = artists.loc[lambda x: x["ArtistId"] == row["ArtistId"], "Name"].iloc[0] # Acceder al string
albums.loc[idx, "ArtistName"] = artist_name
174 ms ± 1.62 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
albums_merge = albums.merge(artists, how="left", on="ArtistId")
2.24 ms ± 2.77 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Existen distintos tipos de unir datos, el ejemplo anterior utiliza un left join. Los cuatro tipos de cruces más comunes:
inner: (default) Retorna aquellos registros donde los valors de columnas utilizadas para los cruces se encuentran en ambas tablas.left: Retorna todos los registros de la tabla colocada a la izquierda, aunque no tengan correspondencia en la tabla de la derecha.right: Retorna todos los registros de la tabla colocada a la derecha, aunque no tengan correspondencia en la tabla de la izquierda.outer: Retorna todos los valores de ambas tablas, tengan correspondencia o no.
La siguiente imagen explica el resultado que se obtiene con los distintos tipos de cruces.
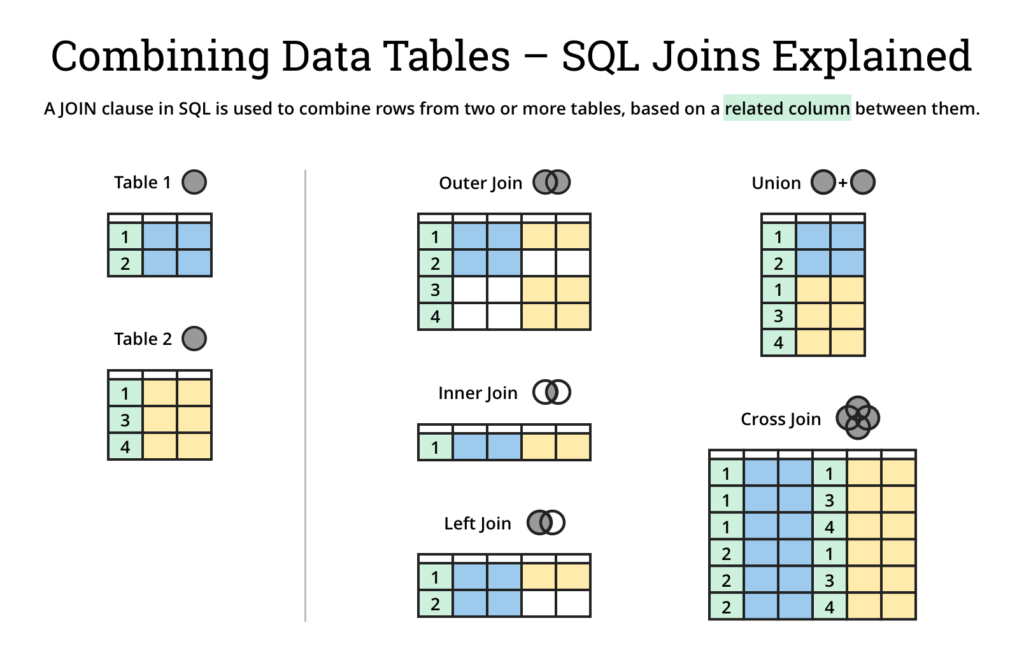

Veamos otros ejemplitos
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
Left Merge
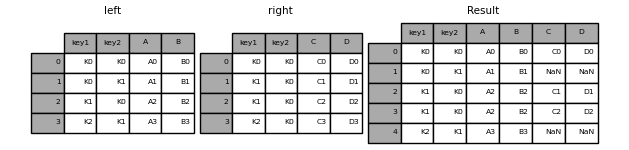
pd.merge(left, right, on=['key1', 'key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
Right Merge

pd.merge(left, right, how='right', on=['key1', 'key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
| 3 | K2 | K0 | NaN | NaN | C3 | D3 |
Outer Merge
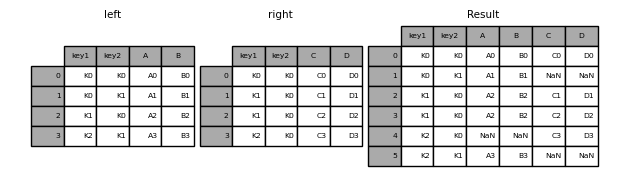
pd.merge(left, right, how='outer', on=['key1', 'key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
| 5 | K2 | K0 | NaN | NaN | C3 | D3 |
Inner Merge

pd.merge(left, right, how='inner', on=['key1', 'key2'])
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
Problemas de llaves duplicadas
Cuando se quiere realizar el cruce de dos tablas, pero an ambas tablas existe una columna (key) con el mismo nombre, para diferenciar la información entre la columna de una tabla y otra, pandas devulve el nombre de la columna con un guión bajo x (key_x) y otra con un guión bajo y (key_y)
left2 = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
right2 = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
pd.merge(left2, right2, on='B', how='outer')
| A_x | B | A_y | |
|---|---|---|---|
| 0 | 1 | 2 | 4 |
| 1 | 1 | 2 | 5 |
| 2 | 1 | 2 | 6 |
| 3 | 2 | 2 | 4 |
| 4 | 2 | 2 | 5 |
| 5 | 2 | 2 | 6 |
Considera que merge también se puede usar como método, por lo que es posible concatener varias operaciones.
Ejemplo: Retornar un dataframe con el nombre de todas las canciones, su álbum y artista, ordenados por nombre de artista, album y canción.
tracks = chinook_query("select * from tracks")
albums = chinook_query("select * from albums")
artists = chinook_query("select * from artists")
tracks.head()
| TrackId | Name | AlbumId | MediaTypeId | GenreId | Composer | Milliseconds | Bytes | UnitPrice | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | For Those About To Rock (We Salute You) | 1 | 1 | 1 | Angus Young, Malcolm Young, Brian Johnson | 343719 | 11170334 | 0.99 |
| 1 | 2 | Balls to the Wall | 2 | 2 | 1 | None | 342562 | 5510424 | 0.99 |
| 2 | 3 | Fast As a Shark | 3 | 2 | 1 | F. Baltes, S. Kaufman, U. Dirkscneider & W. Ho... | 230619 | 3990994 | 0.99 |
| 3 | 4 | Restless and Wild | 3 | 2 | 1 | F. Baltes, R.A. Smith-Diesel, S. Kaufman, U. D... | 252051 | 4331779 | 0.99 |
| 4 | 5 | Princess of the Dawn | 3 | 2 | 1 | Deaffy & R.A. Smith-Diesel | 375418 | 6290521 | 0.99 |
artists.head()
| ArtistId | Name | |
|---|---|---|
| 0 | 1 | AC/DC |
| 1 | 2 | Accept |
| 2 | 3 | Aerosmith |
| 3 | 4 | Alanis Morissette |
| 4 | 5 | Alice In Chains |
(
tracks.rename(columns={"Name": "TrackName"})
.merge(
albums.rename(columns={"Title": "AlbumName"}),
how="left",
on="AlbumId"
)
.merge(
artists.rename(columns={"Name": "ArtistName"}),
how="left",
on="ArtistId"
)
.loc[:, ["TrackName", "AlbumName", "ArtistName"]]
.sort_values(["ArtistName", "AlbumName", "TrackName"])
)
| TrackName | AlbumName | ArtistName | |
|---|---|---|---|
| 11 | Breaking The Rules | For Those About To Rock We Salute You | AC/DC |
| 10 | C.O.D. | For Those About To Rock We Salute You | AC/DC |
| 9 | Evil Walks | For Those About To Rock We Salute You | AC/DC |
| 0 | For Those About To Rock (We Salute You) | For Those About To Rock We Salute You | AC/DC |
| 7 | Inject The Venom | For Those About To Rock We Salute You | AC/DC |
| ... | ... | ... | ... |
| 3154 | Sem Essa de Malandro Agulha | Ao Vivo [IMPORT] | Zeca Pagodinho |
| 3150 | Seu Balancê | Ao Vivo [IMPORT] | Zeca Pagodinho |
| 3151 | Vai Adiar | Ao Vivo [IMPORT] | Zeca Pagodinho |
| 3163 | Verdade | Ao Vivo [IMPORT] | Zeca Pagodinho |
| 3148 | Vivo Isolado Do Mundo | Ao Vivo [IMPORT] | Zeca Pagodinho |
3503 rows × 3 columns