
Visualización Declarativa¶
Es un paradigma de visualización en donde se busca preocuparse de los datos y sus relaciones, más que en detalles sin mayor importancia. Algunas características son:
Se especifica lo que se desea hacer.
Los detalles se determinan automáticamente.
Especificación y Ejecución están separadas.
A modo de resumen, se refiere a construir visualizaciones a partir de los siguientes elementos:
Data
Transformation
Marks
Encoding
Scale
Guides
Para una visualización declarativa adecuata, los datos deben encontrarse en el formato Tidy, es decir:
Cada variable corresponde a una columna.
Cada observación corresponde a una fila.
Cada tipo de unidad de observación corresponde a una tabla.
Más detalles puedes ser encontrados en el siguiente link.
Un ejemplo de datos Tidy:
import pandas as pd
df = pd.DataFrame({
"ID": range(5),
"Color": ["Azul", "Rojo", "Azul", "Azul", "Rojo"],
"Duración": [1, 1, 3, 3, 3]
})
df.head()
| ID | Color | Duración | |
|---|---|---|---|
| 0 | 0 | Azul | 1 |
| 1 | 1 | Rojo | 1 |
| 2 | 2 | Azul | 3 |
| 3 | 3 | Azul | 3 |
| 4 | 4 | Rojo | 3 |
Un ejemplo de datos NO Tidy
df.pivot(index="ID", columns="Color", values="Duración")
| Color | Azul | Rojo |
|---|---|---|
| ID | ||
| 0 | 1.0 | NaN |
| 1 | NaN | 1.0 |
| 2 | 3.0 | NaN |
| 3 | 3.0 | NaN |
| 4 | NaN | 3.0 |
No es Tidy puesto que la variable “Color” utiliza más de una columna.
Idea: Buenas implementaciones pueden influir en buenas conceptualizaciones.


Diferencias entre enfoques¶
Imperativa |
Declarativa |
|---|---|
Especificar cómo se debe hacer algo |
Especificar qué se quiere hacer |
Especificación y ejecución entrelazadas |
Separar especificación de ejecución |
Colocar un círculo rojo aquí y un círculo azul acá |
Mapear |
El Iris dataset es un conjunto de datos famoso por ser un buen ejemplo, por lo que nos servirá para mostrar una de las mayores diferencias entre una visualización imperativa (como matplotlib) versus una declarativa (como altair).
import altair as alt
from vega_datasets import data # Una librería con muchos datasets
alt.themes.enable('opaque') # Para quienes utilizan temas oscuros en Jupyter Lab
ThemeRegistry.enable('opaque')
# Una breve descripción
data.iris?
iris = data.iris()
iris.head()
| sepalLength | sepalWidth | petalLength | petalWidth | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
iris.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepalLength 150 non-null float64
1 sepalWidth 150 non-null float64
2 petalLength 150 non-null float64
3 petalWidth 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
iris.describe(include="all")
| sepalLength | sepalWidth | petalLength | petalWidth | species | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150 |
| unique | NaN | NaN | NaN | NaN | 3 |
| top | NaN | NaN | NaN | NaN | setosa |
| freq | NaN | NaN | NaN | NaN | 50 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 | NaN |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 | NaN |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 | NaN |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 | NaN |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 | NaN |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 | NaN |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 | NaN |
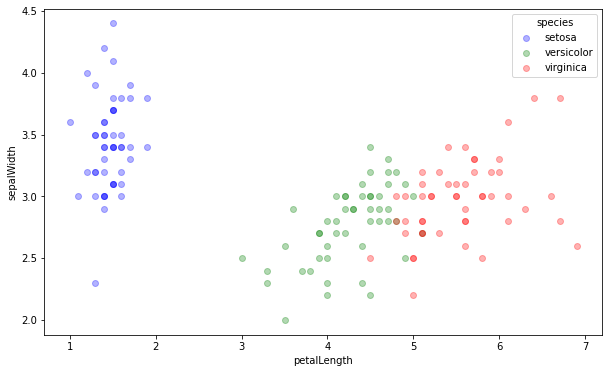
El ejemplo clásico consiste en graficar sepalWidth versus petalLength y colorear por especie.
Imperativo¶
En matplotlib sería algo así:
import matplotlib.pyplot as plt
color_map = dict(zip(iris["species"].unique(),
["blue", "green", "red"]))
plt.figure(figsize=(10, 6))
for species, group in iris.groupby("species"):
plt.scatter(group["petalLength"],
group["sepalWidth"],
color=color_map[species],
alpha=0.3,
edgecolor=None,
label=species,
)
plt.legend(frameon=True, title="species")
plt.xlabel("petalLength")
plt.ylabel("sepalWidth")
plt.show()
Declarativo¶
En altair sería algo así:
alt.Chart(iris).mark_point().encode(
x="petalLength",
y="sepalWidth",
color="species"
)
Spoiler: Solo bastan un par de líneas extras para crear un gráfico interactivo!
alt.Chart(iris).mark_point().encode(
x="petalLength",
y="sepalWidth",
color="species",
tooltip="species"
).interactive()
Altair¶
Altair is a declarative statistical visualization library for Python, based on Vega and Vega-Lite, and the source is available on GitHub.
With Altair, you can spend more time understanding your data and its meaning. Altair’s API is simple, friendly and consistent and built on top of the powerful Vega-Lite visualization grammar. This elegant simplicity produces beautiful and effective visualizations with a minimal amount of code.
Data¶
Los datos en Altair son basados en Dataframe de Pandas, los cuales deben ser Tidy para una mejor experiencia.
El objeto Chart es el fundamental, pues tiene como argumento los datos.
# Utilizaremos estos datos como ejemplo
import pandas as pd
df = pd.DataFrame({'a': list('CCCDDDEEE'),
'b': [2, 7, 4, 1, 2, 6, 8, 4, 7]})
import altair as alt
chart = alt.Chart(df)
Mark¶
¿Cómo queremos que se vean los datos? La respuesta está en los marks, que en Altair corresponden a un método de un objeto Chart.
alt.Chart(df).mark_point()
La representación anterior consiste en un solo punto, pues aún no se ha especificado las posiciones de los puntos.
Encoding¶
Canales asociados a columnas de los datos con tal de separar visualmente los elementos (que para estos datos se están graficando puntos).
Por ejemplo, es posible codificar la variable a con el canal x, que representa el eje horizontal donde se posicionan los puntos. Esto es posible mediante el método encode de los objetos Charts.
alt.Chart(df).mark_point().encode(
x='a',
)
Los principales canales de encoding son x, y, color, shape, size, etc. los cuales se pueden designar utilizando el nombre de la columna asociada a los datos.
Finalmente, separemos la posición vertical asignando el canal y, que como te imaginas, corresponde al eje vertical.
alt.Chart(df).mark_point().encode(
x='a',
y='b'
)
Transformación¶
Altair permite incluso transformar datos con tal de entregar mayor flexibilidad, para ello dispone de una sintaxis incorporada para Agregaciones. Por ejemplo, para calcular el promedio.
alt.Chart(df).mark_point().encode(
x='a',
y='average(b)'
)
Aunque en realidad es más acertado utilizar gráficos de barra para mostrar agregaciones. Es tan fácil como cambiar el método mark_point() por mark_bar().
alt.Chart(df).mark_bar().encode(
x='a',
y='average(b)'
)
Personalización¶
Por defecto, Altair a través de Vega-Lite realiza algunas elecciones sobre las propiedades por defecto en cada visualización. Sin embargo, Altair también provee una API para personalizar los gráficos. Por ejemplo, es posible especificar el título de cada eje utilizando los atributos de los canales. Inclusive es posible escoger el color de los marks.
alt.Chart(df).mark_bar(color='firebrick').encode(
y=alt.Y('a', axis=alt.Axis(title='category')),
x=alt.X('average(b)', axis=alt.Axis(title='avg(b) by category'))
)
En el ejemplo anterior no basta con solo el nombre de la columna, es necesario crear el objeto alt.__ correspondiente a los canales.
Otro ejemplo útil consiste en juntar dos gŕaficos en una misma figura.
vertical_chart = alt.Chart(df).mark_bar().encode(
x='a',
y='average(b)'
)
horizontal_chart = alt.Chart(df).mark_bar(color='firebrick').encode(
y=alt.Y('a', axis=alt.Axis(title='category')),
x=alt.X('average(b)', axis=alt.Axis(title='avg(b) by category'))
)
vertical_chart | horizontal_chart
Inclusive se puden sumar!
vertical_chart_point = alt.Chart(df).mark_point(color='firebrick').encode(
x='a',
y='average(b)'
)
vertical_chart + vertical_chart_point
Gráfico a Gráfico¶
Gráfico de Barras¶
source = pd.DataFrame({
'a': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'],
'b': [28, 55, 43, 91, 81, 53, 19, 87, 52]
})
alt.Chart(source).mark_bar().encode(
x='a',
y='b'
)
Añadir una capa de complejidad, ya sea diferenciar por color, es tan simple como:
source = data.barley() # Datos de cultivos
alt.Chart(source).mark_bar().encode(
x='year:O',
y='sum(yield):Q',
color='year:N',
column='site:N'
)
Histogramas¶
Este ejemplo muesrta un histograma con una línea superpuesta indicando la media global.
source = data.cars()
base = alt.Chart(source)
hist = base.mark_bar().encode(
x=alt.X('Horsepower:Q', bin=True),
y='count()'
)
rule = base.mark_rule(color='red').encode(
x='mean(Horsepower):Q',
size=alt.value(5)
)
hist + rule
Gráfico de Líneas¶
import numpy as np
x = np.arange(100)
source = pd.DataFrame({
'x': x,
'f(x)': np.sin(x / 5)
})
alt.Chart(source).mark_line().encode(
x='x',
y='f(x)'
)
Este ejemplo muestra un gráfico de líneas de series múltiples de los precios de cierre diarios de las acciones de AAPL, AMZN, GOOG, IBM y MSFT entre 2000 y 2010.
source = data.stocks()
alt.Chart(source).mark_line().encode(
x='date',
y='price',
color='symbol'
)
Scatter Plot¶
source = data.cars()
alt.Chart(source).mark_circle(size=60).encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
)
Un scatter plot con una superposición media continua. En este ejemplo, se utiliza una ventana de 30 días para calcular la media de la temperatura máxima alrededor de cada fecha.
source = data.seattle_weather()
line = alt.Chart(source).mark_line(
color='red',
size=2
).transform_window(
rolling_mean='mean(temp_max)',
frame=[-15, 15]
).encode(
x='date:T',
y='rolling_mean:Q'
)
points = alt.Chart(source).mark_point().encode(
x='date:T',
y=alt.Y('temp_max:Q',
axis=alt.Axis(title='Max Temp'))
)
points + line
Gráfico de Barras de Error¶
Este ejemplo muestra barras de error con desviación estándar utilizando diferentes datos de rendimiento de cultivos en la década de 1930.
source = data.barley()
error_bars = alt.Chart(source).mark_errorbar(extent='stdev').encode(
x=alt.X('yield:Q', scale=alt.Scale(zero=False)),
y=alt.Y('variety:N')
)
points = alt.Chart(source).mark_point(filled=True, color='black').encode(
x=alt.X('yield:Q', aggregate='mean'),
y=alt.Y('variety:N'),
)
error_bars + points
Gráficos de Area¶
Este ejemplo muestra como hacer un gráfico de área apilado y normalizado.
source = data.iowa_electricity()
alt.Chart(source).mark_area().encode(
x="year:T",
y=alt.Y("net_generation:Q"),
color="source:N"
)
Este ejemplo muestra como hacer un gráfico de área apilado y normalizado.
source = data.iowa_electricity()
alt.Chart(source).mark_area().encode(
x="year:T",
y=alt.Y("net_generation:Q", stack="normalize"),
color="source:N"
)
Mapas de Calor¶
Este ejemplo muestra un mapa de calor simple para mostrar datos cuadriculados.
# Compute x^2 + y^2 across a 2D grid
x, y = np.meshgrid(range(-5, 5), range(-5, 5))
z = x ** 2 + y ** 2
# Convert this grid to columnar data expected by Altair
source = pd.DataFrame({'x': x.ravel(),
'y': y.ravel(),
'z': z.ravel()})
alt.Chart(source).mark_rect().encode(
x='x:O',
y='y:O',
color='z:Q'
)
Este ejemplo muestra un gráfico de texto en capas sobre un mapa de calor utilizando el conjunto de datos de automóviles.
source = data.cars()
# Configure common options
base = alt.Chart(source).transform_aggregate(
num_cars='count()',
groupby=['Origin', 'Cylinders']
).encode(
alt.X('Cylinders:O', scale=alt.Scale(paddingInner=0)),
alt.Y('Origin:O', scale=alt.Scale(paddingInner=0)),
).properties(
width=400,
height=400
)
# Configure heatmap
heatmap = base.mark_rect().encode(
color=alt.Color('num_cars:Q',
scale=alt.Scale(scheme='viridis'),
legend=alt.Legend(direction='horizontal')
)
)
# Configure text
text = base.mark_text(baseline='middle').encode(
text='num_cars:Q',
color=alt.condition(
alt.datum.num_cars > 100,
alt.value('black'),
alt.value('white')
)
)
# Draw the chart
heatmap + text
Mapas¶
Este ejemplo muestra un mapa coroplético de la tasa de desempleo por condado en los EE. UU.
counties = alt.topo_feature(data.us_10m.url, 'counties')
source = data.unemployment.url
alt.Chart(counties).mark_geoshape().encode(
color='rate:Q'
).transform_lookup(
lookup='id',
from_=alt.LookupData(source, 'id', ['rate'])
).project(
type='albersUsa'
).properties(
width=500,
height=300
)
Este ejemplo muestra una visualización geográfica en capas que muestra las posiciones de los aeropuertos de EE. UU. En un contexto de estados de EE. UU.
airports = data.airports.url
states = alt.topo_feature(data.us_10m.url, feature='states')
# US states background
background = alt.Chart(states).mark_geoshape(
fill='lightgray',
stroke='white'
).properties(
width=500,
height=300
).project('albersUsa')
# airport positions on background
points = alt.Chart(airports).transform_aggregate(
latitude='mean(latitude)',
longitude='mean(longitude)',
count='count()',
groupby=['state']
).mark_circle().encode(
longitude='longitude:Q',
latitude='latitude:Q',
size=alt.Size('count:Q', title='Number of Airports'),
color=alt.value('steelblue'),
tooltip=['state:N','count:Q']
).properties(
title='Number of airports in US'
)
background + points
El límite es la imaginación??¶
Todos los ejemplos anteriores fueron recopilados de la Galería de Ejemplos de Altair (link), como podrás darte cuenta, son muchos menos que los ofrecidos por matplotlib. Altair es una librería nueva, alrededor de 3 años, versus los 17 años de matplotlib.
Si bien crear gráficos “comunes” es mucho menos verboso, al querer realizar gráficos de bajo nivel matplotlib es el claro ganador. Dependiendo de tus necesidades del momento, debes saber escoger una u otra librería, son complementarias y no enemigas!
Sin embargo, eso no quita el hecho que en Altair se puedan realizar gráficos “poco convencionales”.
"""
Isotype Visualization shows the distribution of animals across UK and US,
using unicode emoji marks rather than custom SVG paths
(see https://altair-viz.github.io/gallery/isotype.html).
This is adapted from Vega-Lite example https://vega.github.io/vega-lite/examples/isotype_bar_chart_emoji.html.
"""
source = pd.DataFrame([
{'country': 'Great Britain', 'animal': 'cattle'},
{'country': 'Great Britain', 'animal': 'cattle'},
{'country': 'Great Britain', 'animal': 'cattle'},
{'country': 'Great Britain', 'animal': 'pigs'},
{'country': 'Great Britain', 'animal': 'pigs'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'Great Britain', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'cattle'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'pigs'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'},
{'country': 'United States', 'animal': 'sheep'}
])
alt.Chart(source).mark_text(size=45, baseline='middle').encode(
alt.X('x:O', axis=None),
alt.Y('animal:O', axis=None),
alt.Row('country:N', header=alt.Header(title='')),
alt.Text('emoji:N')
).transform_calculate(
emoji="{'cattle': '🐄', 'pigs': '🐖', 'sheep': '🐏'}[datum.animal]"
).transform_window(
x='rank()',
groupby=['country', 'animal']
).properties(width=550, height=140)